Data Extractor如何为新类型的文件提取GREP正则表达式
在本文中,我们将介绍如何在Data Extractor搜索引擎引用中添加新类型的文件。
让我们考虑一个例子 – 客户要求我们恢复* .qbw文件。
首先,我们需要让客户向我们提供至少三个此类工作文件。
然后我们在HexEdit中打开它们并按对比较(通过Ctrl + A复制一个文件加上Ctrl + C,将光标设置在第二个文件的第一个字节上并按Ctrl + M)。 结果将是这样的:
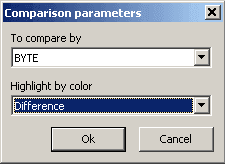

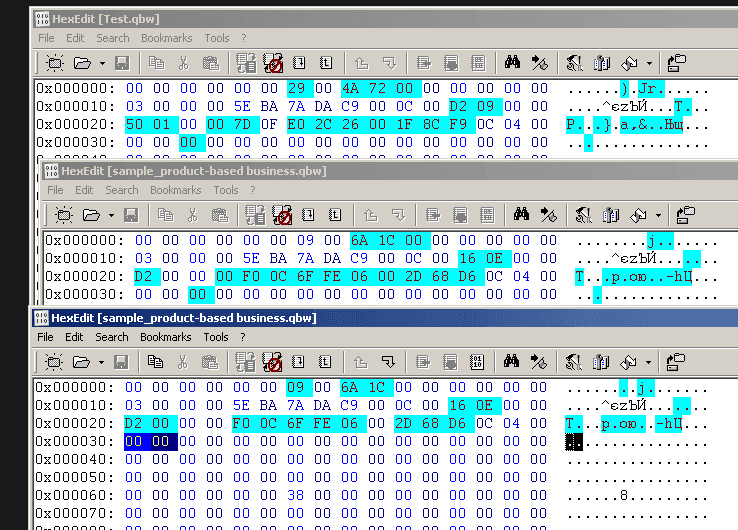
突出显示的字节不同。 我们需要定义标题中的哪些字节是相同的。
在我们的例子中,前6个字节是相同的,并用零填充。 让我们将这个标志添加到GREP表达式中。 使用内置的DataExtractor插件有一种简单的方法。 只需在DE中打开一个好的文件作为外部文件。
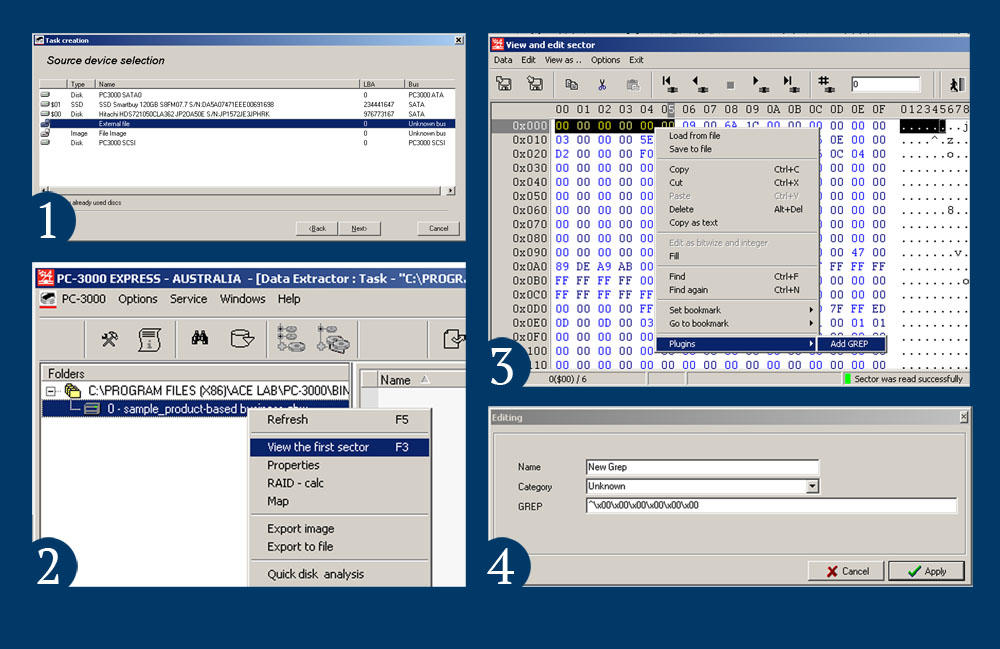
所以在这里我们得到了^ X00 X00 X00 X00 X00 x00的正则表达式。
要检查它是否有效,我们可以将它应用于同一个文件,它必须只返回一个结果,而且LBA必须为0.如果你有更多的那个像下面的图片那么它定义意味着你的表达式很弱。

GREP表达式必须是唯一的,并且尽可能防止进入具有某些标头的其他类型的结果文件。 至少我建议总是检查引用中的任何表达式是否从start开始具有相同的字节。 如果你得到的结果超出预期,或者文件无法在他们创建的程序中打开 – 可能你的GREP表达式很弱。
另外现在在Add GREP插件中无法选择多个字符串并自动从中创建正则表达式。 但是你总是可以手动完成,下表对它很有用:
| 符号 | 含义 |
| ? | 任何符号 |
| . | 任何符号 |
| * | 任何数量的任何符号 |
| 00 | 八进制编码中的符号 |
| 999 | 十进制编码中的符号 |
| xHH | 十六进制编码中的符号 |
| %x | 特殊字符集(如 W, w, N, n, A, a, X, x…) |
| ^ | 从字符串的开头 |
| @nnn | 从nnn位置开始 (@-nnn – from end) |
如果你没有在表格中找到所需的表达式,你可以在维基百科中阅读它,表达式几乎与任何流行的编程语言一样。
在我们的示例中,* .qwb文件类型的正确表达式为^ {16}(.) x03 x00 x00 x00 x5E xBA x7A xDA xC9 x00 x0C x00
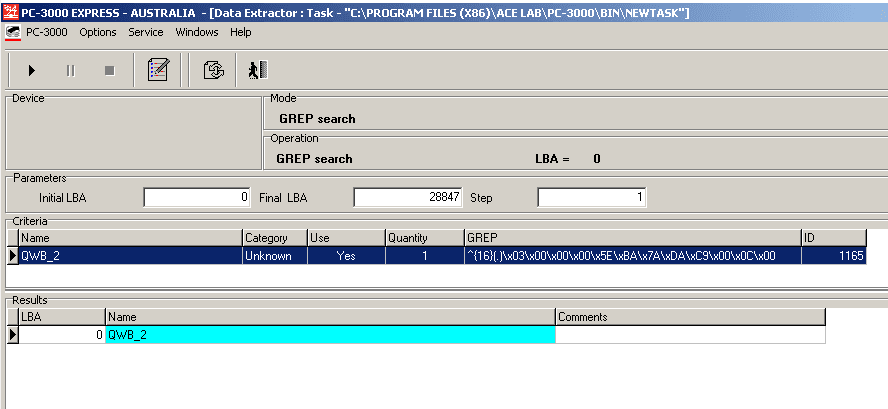
正如你在上面的图片中看到的,只返回了一个结果,它从LBA0开始

